Sentence Classification
Sentence Classification
针对句子的分类,理解的处理是自然语言处理领域中很重要的研究领域。 这里将介绍以下几种句子的分类方法:
- Bag-of-words
- Word2Vec
- Doc2Vec
- TF-IDF
1. Bag-of-words
Bag-of-words是对句子中单词的出现次数的向量表示。 比如说 {I, have, a, pen, I, have, an, apple} 通过使用Bag-of-words向量表示时, 单词的顺序为: I, have, a, pen, an, apple 对应的单词频度为: [2,2,1,1,1,1]
Bag-of-words的优点: 简单易懂, 计算效率高。
Bag-of-words的缺点:
a. 没有考虑单词的出现顺序, 只要使用了相同的单词,那么表达出来的向量就是一样的。
b. 不能表达语义,比如,programming, python, plane 三个单词的距离是一样的。 (按语义理解,programming和python应该是相近的)
2. Word2Vec
Word2Vec是什么
Word2Vec是单词的向量表示方法,对单词的表示,常见的是使用one-hot向量的方法。 与one-hot vector相比Word2Vec可以表达单词的语义,以及其文法, 经过word2vec表示的单词,不在是一个单独的词,而是包含了上下文统计信息的一种向量表达。
比如, 根据{I, have, a, pen, I, have, an, apple}建立一个词表, 那么我们可以得到I, have, a, pen, an, apple 当我们对pen使用one-hot表示时,可以得到[0,0,0,1,0,0]. apple为[0,0,0,0,0,1]
这种表达的缺点是,当词表中增加新单词时, 向量的维数就要增加。 另外也无法表达单词与单词之间的相互关系(相似,反义词等等)。
Word embedding方法解决了以上的几种缺陷,它支持更复杂的表达, 并且可以支持演算处理。
Word embedding通常表达为一个固定维数的向量,比如200-1000维。 它不是简单的将单词映射为向量,而是通过复杂的演算来对单词进行编码。
Word2Vec训练方法
Word2Vec通过关注文中的单词是否可以交换来学习单词与单词之间的关系。
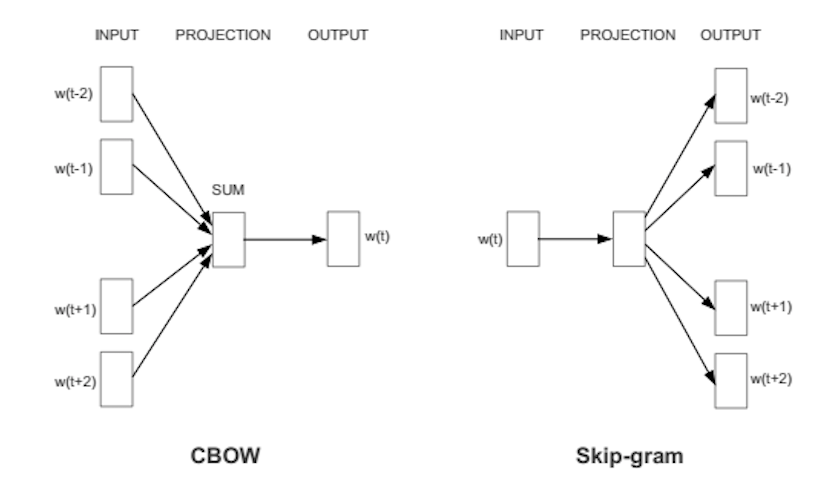
方法1: CBoW (Continuous Bag-of-Words)
CBoW通过使用前后k个单词,来预测当前的对象单词来学习。
方法2: Continuous Skip-gram
Skip-gram使用当前的单词来预测前后k个单词。 此方法在训练数据比较少的情况下,也可以有比较好的精度。 Skip-gram方法对低频词效果更好。
Word2Vec的加减运算
可以进行加减运算 比如可以进行以下运算:
国王 - 男 + 女 = 女王
巴黎 - 法国 + 日本 = 东京
Word2Vec弱点
Word2vec不能很好的表达反义词。 例如:
我喜欢在外面吃饭
我讨厌在外面吃饭
通过这两个句子表达出来的[喜欢]与[讨厌]是没有区别的。
当要开发的功能对反义词有很重要的依赖时, 需要谨慎使用Word2vec。
使用Google pre-trained word2vec model
直接使用Google训练Word2Vec模型, 通常可以得到比较好的性能。 https://code.google.com/archive/p/word2vec/
3. Doc2Vec
与Word2Vec类似,Doc2Vec也有两种计算方式,dmpv(Distributed memory paragraph vector)和DBow(Distributed Bag of Words)。 DBoW是一种考虑单词的顺序的简洁的模型, 其计算效率高效。 dmpv比DBoW更复杂,有更多的参数。
dmpv(Distributed memory paragraph vector)
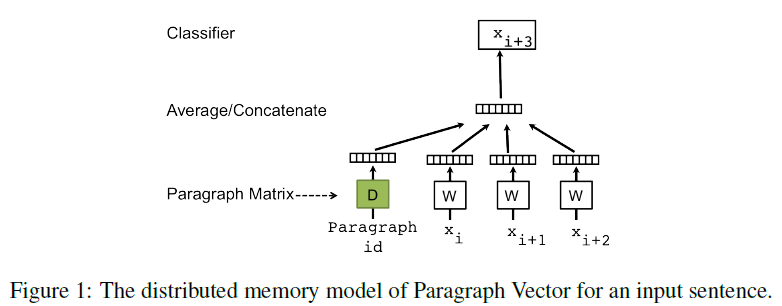
dmpv是基于word2vec的CBoW的方法改进而来。 dmpv增加了Paragraph ID, 通过使用前后的单词来预测对象单词。
DBow(Distributed Bag of Words)
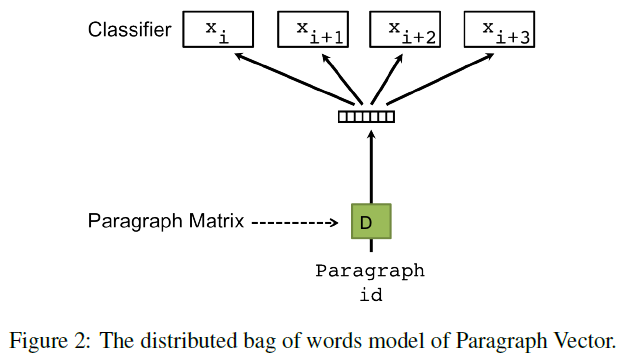
DBoW与Skip-gram方法相似,Skip-gram使用对象单词来预测前后的单词。 DBoW使用Paragraph ID来预测句子。 由于此方法与Bag-of-words类似没有考虑单词前后顺序, 所以被命名为Distributed Bag of Words。 此方法简单,省内存,计算效率高, 但是精度上没有dmpv方法好。
Doc2Vec参数优化
文章[3]中介绍了一些高效训练Doc2Vec的方法。
下表中给出针对不同任务的最优参数设置。
Q-Dup是使用StackExchange的数据,用来检测重复问题
Semantic Textual Similarity (STS)预测句子相似度任务。范围:0~5
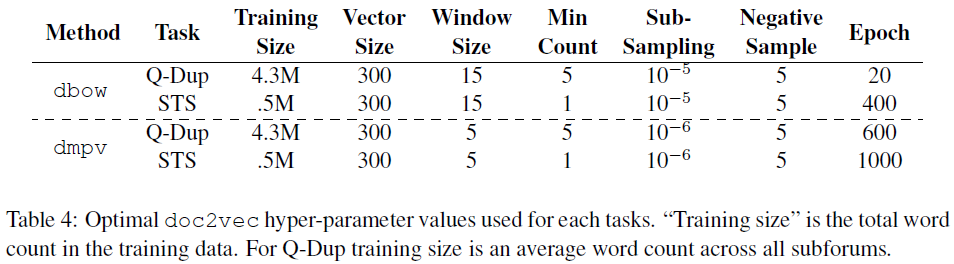
Task:
Vector size: Word2Vec的维数
Window size: 单词前后的单词数
Min Count: 单词出现次数小于此值被忽略
Sub sampling:
Negative Sample:
学习率learning rate从0.25开始线性递减到0.0001。
4. TF-IDF
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF意思是词频(Term Frequency),IDF意思是逆向文件频率(Inverse Document Frequency)。
TFIDF的主要思想是:如果词w在一篇文档d中出现的频率高,并且在其他文档中很少出现,则认为词w具有很好的区分能力,适合用来把文章d和其他文章区分开来。TFIDF实际上是:TF * IDF,TF词频(Term Frequency),IDF逆向文件频率(Inverse Document Frequency)。
TF-IDF计算方法:

TF-IDF值越大,则此单词的区分能力越强。
相关工具
gensim
Others
LDA
Related Paper
[1] Document Embedding with Paragraph Vectors
[2] Distributed Representations of Sentences and Documents
[3] An Empirical Evaluation of doc2vec with Practical Insights into Document Embedding Generation
参考文献:
https://github.com/jhlau/doc2vec#model-hyper-parameter-explanation
http://www.davidsbatista.net/blog/2017/04/01/document_classification/
https://groups.google.com/forum/#!topic/gensim/bEskaT45fXQ
https://github.com/RaRe-Technologies/gensim/blob/develop/docs/notebooks/doc2vec-IMDB.ipynb
https://deepage.net/machine_learning/2017/01/08/doc2vec.html
http://www.ruanyifeng.com/blog/2013/03/tf-idf.html