GAN介绍 - 相关研究课题
GAN是一个相对新的方法, 还有很多的待解决的研究课题。
5.1 不收敛
GAN面对的最大的需要研究者来尝试解决的问题是不收敛问题。
很多的深度模型使用一个优化算法来寻找损失函数的小值的方式来进行训练。 然而有很多的问题会干扰此优化过程, 优化算法通常是一个比较可靠的下降过程。 由于,GAN需要找到针对游戏中两个玩家的平衡。 甚至如果一个玩家通过自己的更新使自己成功下降的时候,可能会使另一个玩家向上走。 有时候两个玩家最终会达到一个平衡,但是也有其他的情景,他们反复的撤销对方的操作,而不能有实质的有用的进展。 这是一个博弈游戏的普遍问题,而不是GAN独有的, 因此针对此问题的解决方案会有很广泛的影响。
为了直观的了解, 梯度导数下降在博弈中(不是优化)是如何执行的, 建议读者现在去完成7.2章的练习题(答案在8.2章)。
同步梯度下降对有些博弈游戏是可以收敛的,但不是全部。
在GAN的极小极大博弈中, Goodfellow et al. (2014b)展示了当在函数空间中进行更新时,同步梯度下降可以收敛。 在实践中, 更新是在参数空间来操作的, 因此依赖于凸属性问题的证据并不适用于此。 当前, 既没有理论的证据来说明当在深度神经网络的参数空间更新时,GAN应该收敛,也没有理论证据证明不能收敛。
在实践中, GAN经常看起来是扰动的, 稍微有点像8.2章中模拟的例子中发生的那样, 意味着他们有时生成一种类型的样本, 有时又生成另一个类型的样本而完全的不能达到平衡状态。
大概GAN遇到的影响其收敛问题是Mode collapse问题。
5.1.1 Mode collapse
Mode collapse, 也被称为Helvetica scenario, 此问题发生于当生成器试图映射几个不同\(z\)的输入到同一个输出点时。 在实际应用中, 完全的mode collapse是很少的, 但是部分的Mode collapse是很常见的。 部分的Mode collapse场景是, 当生成器处理多张包含一样的颜色或者同一个纹理的主题的图像, 或者多个包含一个狗的不同的视角的图像(前者是不同类图像包含相同的信息; 后者是同一类的图片包含不同的信息)。 图22展示了Mode collapse的问题。
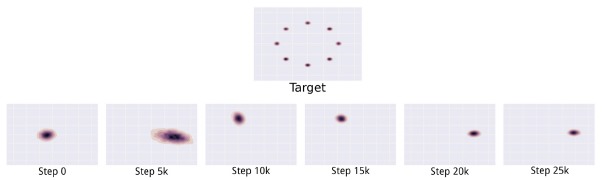
图22: 在一个二维模拟数据上的Mode collapse问题演示。 最上面的是模型需要学习的目标分布\(p_{data}\)。 它是一个二维空间的混合的高斯分布。 在第二行, 我们可以看到随着GAN的学习,不同时间产生了一系列的不同分布。 相对于收敛到一个分布包含所有的训练数据的mode, 生成器仅仅在一个时间点生成其中的一个mode, 并且随着判别器通过学习不断的拒绝一个mode, 在不同的mode间来回切换。 此图片来自 Metz et al. (2016).
Mode collapse的发生可能是因为使用极大极小(maximin)优化与使用极小极大(minimax)优化的不同引起的。 当我们使用极小极大优化时,也就是:
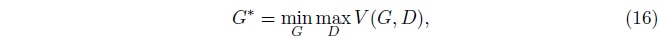
\(G^{*}\)被优化为根据数据的分布来生成样本。 但是当我们将min和max的顺序颠倒以后我们发现
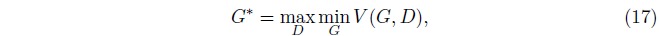
表示生成器的最小化位于优化过程的内循环中。 此时生成器将映射每一个\(z\)到一个\(x\)上, 对应判别器判定为真而不是假的置信度。 从同步梯度下降的角度看min max并没有比max min更有优势, 反之亦然。
正如3.2.5章讨论的, Mode collapse不像是被任何特别的损失函数引起的。 通常的主张是,mode collapse是因为使用Jensen-Shannon散度引起的, 但是这好像也不是实际情况, 因为GAN使用最小化\(D_{KL}(p_{data}||p_{model})\)近似时也面临同样的问题, 即便是在比Jensen-Shannon散度要求的mode少的情况下,也会出现mode collapse问题。
因为Mode collapse问题, GAN的应用经常被限定到那些模型只产生比较少的不同输出的问题上。 只要GAN能够找到那些可以被接受的少量的输出,那么它就是有用的。 一个例子是text-to-image生成任务, 在这种任务中,输入一个图像的描述,输出是一个符合此描述的图像。 图23对此种任务进行了描述。 最近一个工作, Reed et al. (2016a),展示了针对此类任务, 其他的模型比GAN有更高的输出多样性(图24), 但是StachGAN(Zhang et al., 2016)展示了相比以前的基于GAN的方法也有更高的输出多样性(图25).

图23: 使用GAN来做Text-to-image的生成任务。 图像来自Reed et al.(2016b)

图24: 由于mode collapse问题,在text-to-image任务中,GAN有较差的输出多样性。 图片来自Reed et al. (2016a)。

图25: 比其他的基于GAN的text-to-image模型,StackGAN能够有更高的输出多样性。 图片来自Zhang et al. (2016)。
Mode collapse问题很可能是GAN最重要的需要研究者去解决的问题。
一个尝试是minibatch feature (Salimans et al., 2016)。 minibatch features基本的思路是允许判别器比较一个样本与一个minibatch的生成样本和一个minibatch的真实样本。 通过测度与这些潜在空间中的其他样本的距离, 判别器可以判定是否一个样本显著的与其他生成样本相似。 Minibatch features工作的很好。 强烈建议直接复制与那些与相关介绍文章一起发布的Theano/TensorFlow代码, 因为一些小的特征定义的改动会导致很大的性能的下降。
Minibatch GAN在CIFAR-10上训练可以得到很好的结果, 多数的样本被识别为CIFAR-10中的特定的类(图26)。 当在128x128 ImageNet上训练时, 很少的样本被识别为属于ImageNet中的具体的类(图27)。 图28展示了一些被精选出来的较好的图片。

图26:Minibatch GAN在CIFAR-10上训练可以得到很好的结果, 多数的样本被识别为CIFAR-10的特定的类(注释: 模型使用Label训练,也就是使用了条件式GAN)

图27: Minibatch GAN在128x128 ImageNet上使用Label来训练产生图像, 有时生成的图像会被识别为ImageNet中的具体的类。

图28: Minibatch GAN在128x128 ImageNet上有时可能产生很好的样本, 这里的图片都是被精心挑选的。
Minibatch GAN很大程度上减少了mode collapse问题,而不是其他问题, 比如计数(counting),预测(perspective)的困难, 以及全局结构(global structure)等一些最显著的缺陷(图29, 30, 31)。 很多这些问题通过设计更好的模型架构应该可以被解决。

图29: 在128x128 ImageNet 上GAN好像有计数(counting)问题,经常产生的动物有错误数量的身体部位。

图30: 在128x128 ImageNet 上GAN在三维预测方面存在一些问题, 经常产生的物体太胖或者在一个轴上被对齐处理。 作为一个对读者判别网络的测试,请试着找出这里面的一张真实的图片。

图31: 在128x128 ImageNet 上GAN好像不善于去协调整体结构, 比如, 放射性奶牛,一个动物同时有四肢动物和两足动物的结构。
另一个解决Mode collapse问题的方法是unrolled GAN (Metz et al., 2016)。 理想情况下, 我们希望优化 \(G^{*}=arg min_{G} max_{D} V(G,D)\)。 在实际操作中, 我们同时对两个玩家跟踪\(V(G,D)\)的梯度,但是当计算G的梯度时, 实际上我们会忽略掉max的操作。 事实上, 在计算\(G\)的损失函数时, 我们应该考虑\(max_{D} V(G,D)\), 并且通过最大化操作来反向传播。 通过最大化操作进行反向传播的策略有很多, 但是很多是不稳定的,比如那些基于隐式微分的方法(implicit differentiation)。 Unrolled GAN的思想是建立一个计算图描述\(k\)步的判别器学习, 然后当计算生成器梯度时通过所有的\(k\)步的学习进行反向传播。 完全优化判别器的函数,将花费上万步, 但是Metz et al. (2016)发现展开(unrolling)很少的几步, 比如说10,或者更少, 也可以显著的减少mode dropping问题。 这个方法还没有用到ImageNet上。 图32显示了unrolled GAN在模拟数据上的效果。

图32: 在一个二维空间,UnrolledGAN可以拟合所有的混合高斯的mode。 图片来自Metz et al. (2016).
5.1.2 其他博弈游戏
如果一个连续,高维,非凸的博弈收敛的理论可以被改善, 或者如果我们可以开发算法来让收敛比同步梯度下降更可靠, 除了GAN以外,还有好多领域都会受益。 即便是仅仅限定在AI研究领域,我们也可以找到很多的应用场景:
- 真正玩游戏的应用, 比如AlphaGO (Silver et al., 2016)
- 安全领域的机器学习, 这类模型必须要拒绝对抗样本 (Szegedy et al., 2014; Goodfellow et al., 2014a).
- 通过domain对抗训练进行Domain adaptation (Ganin et al., 2015).
- 保护隐私的对抗机制 (Edwards and Storkey, 2015).
- 密码系统的对抗机制 (Abadi and Andersen, 2016).
除了此处列举的意外,应该还有很多其他的应用。
5.2 生成模型的评价
另一个很重要的关于GAN的研究方向是目前还不清楚如何定量的去评价生成模型。 模型能得到好的似然值,但可能产生坏的样本, 反之,模型产生好的样本,也可能似然很差。 还没有明确的判定方式来定量的给样本打分。 GAN比其他生成模型难评价是因为比较困难去估计GAN的似然(注: Wu et al. (2016)展示这是可能的)。 Theis et al. (2015) 介绍了很多关于评价生成模型的难点。
5.3 离散输出
设计GAN的生成器唯一强制的需求是生成器必须是可微的。 不幸的是, 这意味着生成器不能产生离散数据, 比如说one-hot的单词或者字符表达。 去掉这个限制是一个很重要的研究方向, 将会解锁GAN应用到NLP的潜力。 这里有至少三个明显的方式可以处理此问题:
- 使用REINFORCE算法 (Williams, 1992).
- 使用concrete distribution (Maddison et al., 2016)或者Gumbel-softmax (Jang et al., 2016).
- 训练生成器来采样可以被解码为离散数据的连续数据。(例如,直接对word embedding采样). [使用生成器做word embedding]
5.4 半监督学习
GAN已经取得高度成功的领域是使用生成模型做半监督学习, 最初的GAN文章中提到过但是没有展示过(Goodfellow et al., 2014b)。
GAN至少从CatGANs (Springenberg, 2015)开始就已经被成功的应用到了半监督学习。 当前, 最好的在MNIST, SVHN, 和 CIFAR-10上的半监督学习的结果是由feature matching GAN得到的 (Salimans et al., 2016)。 通常,模型使用50,000或者更多的标定数据进行训练, 但是feature matching GAN仅仅使用很少的训练数据就可以得到很好的表现。 在好几个使用不同量训练样本(从20到8000)的任务上, 它都得到了最好的性能表现。
使用feature matching GAN来做半监督学习的基本思想是,通过增加一个对应伪样本的辅助的类,将一个\(n\)类的分类问题修改为一个\(n+1\)类的分类问题。 通过将所有的真实的类相加来得到真实样本的概率, 从而可以使用分类器来作为GAN的判别器。 Real/Fake的判定甚至可以使用未标定的真实数据(对应着Real), 和生成器生成的数据(对应着Fake)来训练。 分类器可以使用有限的真实,标定的样本来训练,从而识别真实样本的类别。 这个方法被Salimans et al. (2016) and Odena(2016)同时提出来。 较早的CatGAN使用\(n\)类的判别器而不是\(n+1\)类的判别器。
对GAN的进一步改善有望能够进一步提升半监督学习。
5.5 使用隐变量\(z\)
GAN学习一个关于图像\(x\)的表达\(z\)。 已经知道这个表达可以捕捉\(x\)的有用的,高级的,概要的,有语义的属性, 但是怎么来使用这些信息还面临一些困难。
一个使用\(z\)的障碍是很难通过给出一个\(x\)来获得\(z\)。 Goodfellow et al. (2014b) 建议(但是没有给出对应的实现)使用第二个网络模拟生成器来从\(p(z|x)\)采样, 类似生成器从\(p(x)\)采样。 尽管此思路的完整版本,也就是使用一个完全的通用的神经网络作为encoder并从模拟的\(p(z|x)\)的近似中采样, 没有被成功的实现, 但是Donahue et al. (2016)展示了如何训练一个确定性的编码器(encoder), 并且Dumoulin et al. (2016) 展示了如何通过从高斯先验分布中采样来训练一个编码器网络。 进一步的研究肯定可以帮助开发出更强大的随机编码器。
另一种很好的使用code(\(z\))的方式是训练这个code并使其更有用。 InfoGANs (Chen et al., 2016a)通过来标准化code向量中的一些输入,通过使用一个额外的目标函数来鼓励他们有与\(x\)更高的相互信息。 最终code的输入对应着\(x\)的一些特定有意义的属性, 比如一个脸部图像的光照方向。
5.6 建立与增强学习的连接
研究者已经确认了GAN与actor-critic方法(Pfau and Vinyals, 2016), 反转的增强学习(Finn et al., 2016a)的联系。 并且将GAN应用到了模仿学习中(Imitation Learning, Ho and Ermon, 2016)。 这些与增强学习的联系将会继续推动GAN和增强学习的发展。
[最后修改日期: 2017年6月10日]