GAN介绍 - 为什么学习生成式模型?
人们可能会问为什么要学习生成式模型, 特别是当生成式模型只用来产生数据而不能对密度函数进行估计的情况下。 例如,在图像的应用中, 这类模型好像仅仅是提供更多的图像, 但是我们的世界并不缺少图像。
学习生成式模型有很多的原因,其中包括:
-
生成式模型的训练和采样是一个对我们关于表达和操作高维概率分布问题的能力的非常好的测试。 高维的概率分布问题是一个很重要的问题,其在数学和工程领域有很广泛的应用。
-
生成式模型可以以多种方式被应用到增强学习中(reinforcement learning)。
增强学习可以被分为两大类, model-based和model-free。 model-based算法包含一个生成式模型。 基于时间序列的生成式模型可以用来对未来可能的行为进行模拟。 这类模型可以以多种方式来做规划(planning)和增强学习。
用来做规划的生成式模型, 通过使用当前状态以及智能体(agent)假设的可能的行为做为输入,从而学习到未来状态的条件分布。 智能体可以使用不同的潜在的行为来与模型进行交互,并选择倾向于产生与自己期望状态一致的模型的预测行为。 关于此模型最新的一个例子可以参考, Finn et al. (2016a); 基于此模型的规划学习的例子,请参考, Finn and Levine (2016). </span>另一方式是,将产生式模型用于对假设环境的增强学习, 这样即使发生错误行为也不会造成实际的损失。 通过跟踪以前不同状态被访问的频率,或者不同的行为被尝试的频率,生成式模型也可以用于指导探索者/探险者。 生成式模型,特别是GAN,也可以用于inverse reinforcement learning。 关于与增强学习相关联的相关内容将在5.6章进一步解释。
-
生成式模型可以使用有缺失的数据(missing data)来训练,并且可以对缺失的数据进行预测。 一个缺失数据训练的例子是半监督学习(Semi-supervised learning), 这种情况下很多或者绝大部分的数据都是缺失的。 流行的深度模型都需要大量的标定数据来进行训练才能得到比较好的推广能力。 半监督学习是一种减少标定数据的策略。 此方法可以使用大量的非标定数据来提高模型的推广能力,通常非标定数据是很容易获取的。 生成式模型,特别是GAN可以让半监督学习表现的相当好。 详细内容将在5.4章进一步介绍。
-
生成式模型,以及GAN, 使机器学习可以用于多模(multi-modal)输出问题。 有很多任务,一个输入可能对应多个正确的输出, 每一个输出都是可接受的。 传统的基于平均值的机器学习模型, 比如, 对期望输出和预测输出的均方差(MSE)进行最小化的方法,无法训练此种有多个正确输出的模型。 如图3, 此图介绍了预测视频的下一帧图像的例子。

图3: Lotter et al. (2015) 提供一个对多模数据建模的很好的例子。 在此例子中, 模型被训练来预测视频的下一帧图像。 例子中的视频是用来演示一个可以移动的头部的3D模型。 最左边图像是视频中真实的下一帧图像。 中间的图像是使用MSE方法训练的模型来预测的结果。 此方法通过对真实的下一帧图像与预测的下一帧图像来优化MSE的方法训练模型。 这个模型被强制为只能选择下一帧多个答案中的一个正确答案。 因为下一帧图像有很多的可能性, 这些可能的答案会有些细微的位置上的差别, 单一的答案选择让模型针对这些细微差别做了平均化处理。 从而导致了耳朵消失,眼睛变得模糊。 最右边的图像是使用了额的GAN损失函数, GAN可以允许下一帧有很多可能的正确输出, 并且每一个都是尖锐的(sharp),可以认为是真实,细致的图片。
-
最后, 很多任务本身需要根据分布来产生真实数据。 这种例子有:
-
超高分辨率图片: 这种任务是使用一个低分辨率图片产生高分辨率图片。 只所以需要使用生成式模型是因为需要模型产生并加入比原始输入的图像更多的信息。 一个低分辨率的图像会对应多种可能的高分辨率图像。 模型需要根据概率分布从可能的图像中选出一个。 通过对所有可能的样本做平均化处理会使图像变模糊。 如图4.

图4: Ledig et al. (2016) 展示了非常好的单张高分辨率图像结果, 此组结果显示了使用生成式模型根据多模的分布来生产真实样本的优势。 最左边的图像是原始的高分辨率图像, 然后通过downsample制作低分辨率图像。 最后使用不同的方法来试图恢复高分辨率图像。 Bicubic方法是一种插补方法,没有使用训练数据的统计信息。 SRResNet是一个使用MSE训练的神经网络。 SRGAN是一种基于GAN的神经网络, SRGAN的性能的提升是因为它可以直接的处理有多种正确答案的优化问题,而不是对多种正确的答案做平均化处理,从而只得到一个最好的输出结果。
-
艺术创作任务。 最近的两个项目都演示了生成式模型,特别是GAN,可以被用来制作交互式程序,通过给出想像的粗略的场景来辅助用户创建真实的图像。 参考图5,图6。
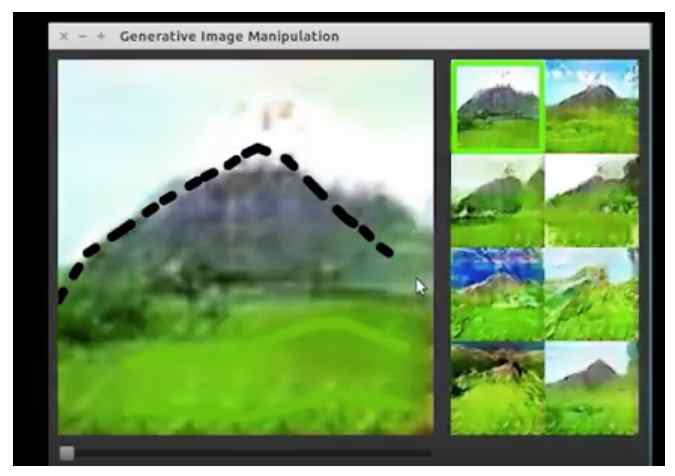
图5: Zhu et al. (2016) 开发了一个交互程序被称为 interactive GAN (iGAN). 用户可以画一个粗糙的草图, 然后iGAN使用GAN来尝试生成最相似的真实图片。 在这个例子中, 当用户粗糙的画了一些绿色线, iGAN生成了长满草的区域, 当用户画了一个黑色的三角形, iGAN就生成了一个细致的山。 艺术创作的应用也是学习使用生成式模型生成图像的一个原因。 iGAN的视频可以查看:https://www.youtube.com/watch?v=9c4z6YsBGQ0
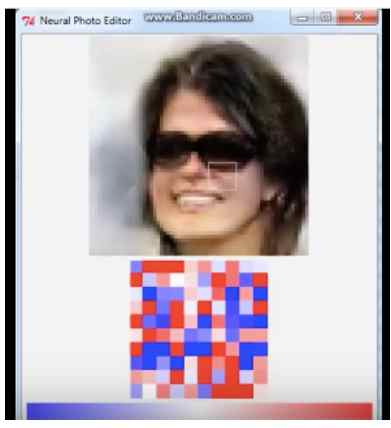
图6: Brock et al. (2016) 开发了内省对抗网络(introspective adversarial networks (IAN) )。 用户对图像做一个简单的修改, 比如将一个区域涂成黑色从而希望加上黑色的头发, IAN可以将这种简单的涂抹转换为用户期望的图片。 对图像进行修改是学习生成式模型的一个理由。 视频请参考:https://www.youtube.com/watch?v=FDELBFSeqQs
-
Image-to-image 转换应用可以将航空图像转换为地图, 或者将素描转换为图像, 请参考图7。 将来,肯定还会有更多的创新的令人惊喜的应用被开发出来。
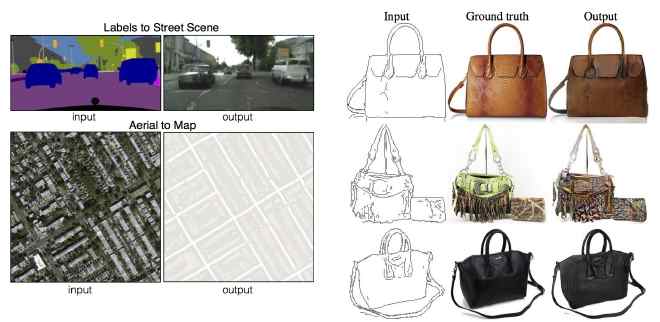
图7: Isola et al. (2016) 演示了很多种图到图转换的应用: 将卫星图像转为地图; 将素描转为真实的照片等等。 因为这个转换过程中每一个输入都对应多个输出, 有必要使用生成式建模来正确的训练模型。 其中Isola et al. (2016) 使用了GAN。 图到图的转换工作给出了很多例子, 这些例子让我们看到一个创新的设计可以帮助我们发现很多意想不到的生成式网络的应用。 未来肯定还会出现更多的创新的应用。
-
所有这些以及其他的生成式模型的应用给我们提供了足够的理由去投入时间和资源来提升生成式模型。
[最终修改于: 2017年6月7日]